6.824 Lab1: MapReduce
1. 分布式计算
处理大规模数据的分布式系统主要分为批处理和流处理系统。
批处理系统:数据被分成不同的批次,一次处理一批,单批的数据规模一般也非常大,适用于对处理时间不敏感的任务。
流处理系统:系统连续不断地接收和处理数据,这类系统对处理速度要求比较高,适用于延迟敏感型任务。
根据处理时间要求的不同,很多时候也将数据处理业务划分为在线和离线业务,在线业务使用流处理系统,离线业务使用批处理系统。
Hadoop、Spark、Flink 是大数据生态中三个重要的分布式计算框架,他们的基本信息如下。其中 Hadoop 是 MapReduce 模型的开源实现。
2. MapReduce
MapReduce 是 Google 在 2004 年发表的论文中提出的编程模型与分布式计算框架 [2],介绍了 Google 当时内部 MapReduce 系统的基本设计原理,也直接启发了后来的 Hadoop,后者成为 MapReduce 的开源实现。
2.1. 架构
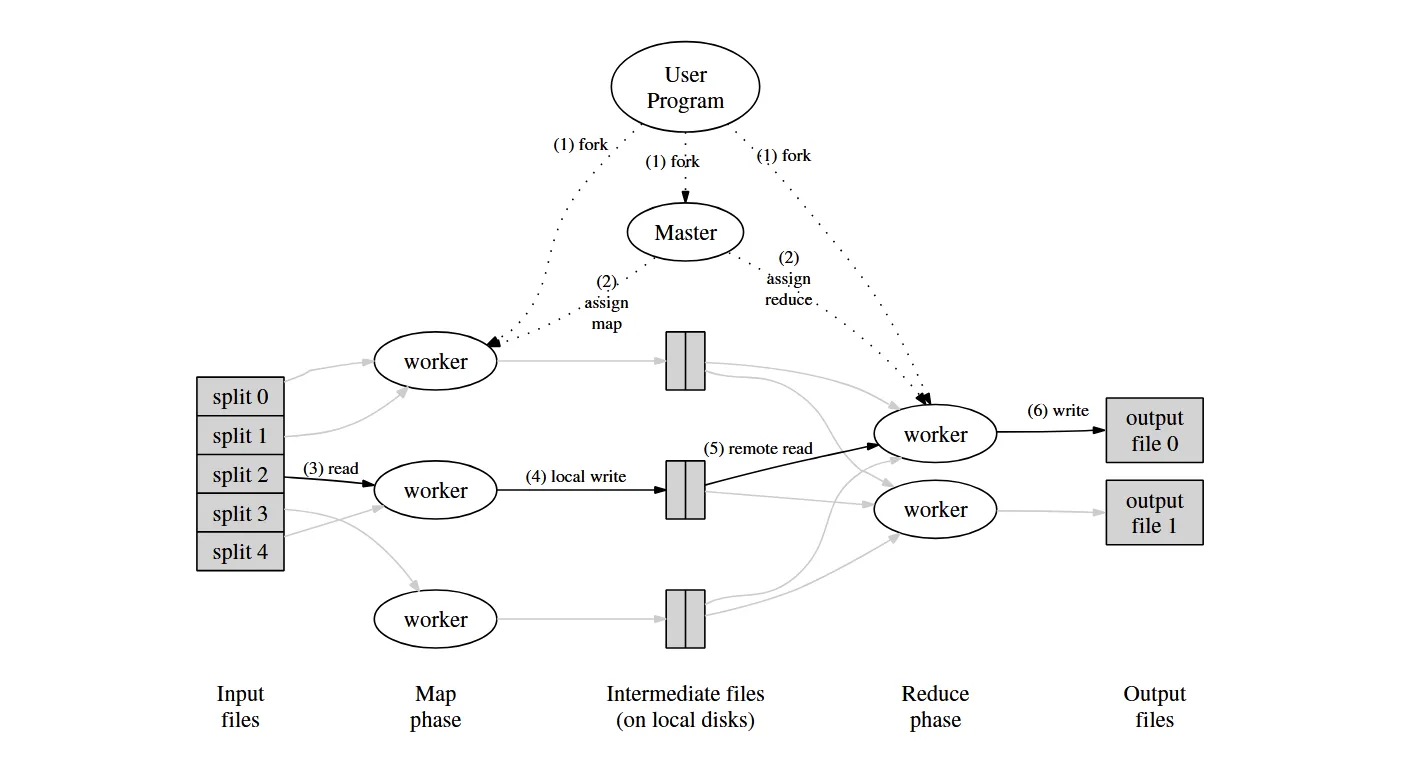
论文中的上图展示了 MapReduce 框架的基本原理,我们按步骤来理解一个作业的执行过程。
1)用户提交计算作业后,框架创建一个 master 节点和若干 worker 节点(worker 本身并没有角色区分)。
2)master 节点将 map 任务与 reduce 任务下发到空闲的 worker。
3)执行 map 任务的 worker 节点读取预先划分好的文件中的一部分,基于用户自定义的 map 函数解析后在内存中生成一批 kv 对。
4)执行 map 任务的 worker 周期性地将 kv 结果写到本地磁盘上(会基于 key 进行分区并写到不同的文件中)
5)执行 reduce 任务的 worker 节点从各个 map 节点读取自己负责的那部分 key 的 kv 数据,先按 key 排序,然后基于用户定义的 reduce 函数进行聚合。
6)执行 reduce 任务的 worker 节点计算完毕后将最终结果写入 GFS(Google File System)中。
以下是个人理解:
若存在 M 个 map 任务与 R 个 reduce 任务,意味着输入文件被划分成了 M 份,以及 map 任务执行完后会按 key 将 kv 数据分区并写到 R 个文件中。
所有 map 任务都执行完毕后,才会进入 reduce 阶段,并开始下发 reduce 任务。否则 reduce 任务读取 key 数据时会发生数据缺失。
2.2. 应用实例
我们来看 MapReduce 中的 HelloWorld 程序:词频统计。以下基于 6.824 lab 中最终完成的 MapReduce 框架。
首先,用户需要定义 map 与 reduce 函数。
package main
//
// a word-count application "plugin" for MapReduce.
//
// go build -buildmode=plugin wc.go
//
import "6.5840/mr"
import "unicode"
import "strings"
import "strconv"
// The map function is called once for each file of input. The first
// argument is the name of the input file, and the second is the
// file's complete contents. You should ignore the input file name,
// and look only at the contents argument. The return value is a slice
// of key/value pairs.
func Map(filename string, contents string) []mr.KeyValue {
// function to detect word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// split contents into an array of words.
words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{}
for _, w := range words {
kv := mr.KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
// The reduce function is called once for each key generated by the
// map tasks, with a list of all the values created for that key by
// any map task.
func Reduce(key string, values []string) string {
// return the number of occurrences of this word.
return strconv.Itoa(len(values))
}某个 map 任务执行完后,会输出下面的中间 kv 数据到本地文件。
George 1
George 1
Canon 1
Chasuble 1
Vanbrugh 1
George 1
Half 1
a 1
piano 1
the 1
the 1
the 1
...某个 reduce 任务执行完后,会得到下面的最终统计结果。
AFTER 2
AS 10
Act 2
Africa 1
Agnew 1
Aha 3
Albertus 3
Alfonso 1
Algernon 271
...2.3. 关键问题
MapReduce 系统的实现中存在以下关键问题 [1]。
容错
worker 节点故障:若 master 节点认为某个 worker 节点已经失联,会将该 worker 节点的任务重新分发给其它健康的空闲 worker。若该 worker 执行的是 reduce 任务,且任务已经完成,则不需要重新分发,因为 reduce 任务的结果是写在 GFS 中的。
master 节点故障:可以通过让 master 周期性地往磁盘上写入 checkpoint 来提供 master 失败时的恢复依据。但由于只有一个 master,失败的概率比较低(相对于分布式任务),文章中提到当时的内部实现会直接终止整个作业,由用户决定是否重试。
网络带宽问题
在 2004 年,网络带宽还是一个相当匮乏的资源,因此任务调度需要考虑存储所在的位置,从而提高数据传输的效率。但随着基础设施的扩展和升级,系统对这种存储位置优化的依赖程度已经降低了。
“落伍者”问题
MapReduce 在作业快完成的时候,会启动一些备用的任务进程来执行剩余仍在处理中的任务,避免因为个别任务运行过长(很可能是故障)而拉长整个作业的运行时间。
跳过损坏的记录
当 master 看到某个任务总是失败时,可以让用户决定是否跳过它。因为这可能是由用户程序引入并由某些记录触发的 bug。而在一个大型作业中,跳过一些子任务有时候不会对结果产生影响。
3. Lab 实现
我在 lab 中完成了一个本地版本的 MapReduce 框架,不过 lab 也提到了可以将其改进为运行在不同机器上的分布式框架。在该实现中, master 被称为 coordinator。Coordinator 是有状态的,维护了所有 map/reduce 任务的状态。而 worker 是完全无状态的,它只负责向 coordinator 申请任务、执行任务并通知 coordinator 任务完成。Worker 与 coordinator 之间通过 rpc 进行通信。
3.1. 数据结构
// coordinator就是master
type Coordinator struct {
mutex sync.Mutex
// 用户作业的输入文件
files []string
// 用户设定的reduce任务数目
nReduce int
// 某个map/reduce任务的超时时间,如果超时coordinator需要重新下发该任务
timeout time.Duration
// 所有map任务的列表
mapTasks []MRTask
// 所有reduce任务的列表
reduceTasks []MRTask
// 标记是否全部map任务都完成了
mapDone bool
// 标记是否全部reduce任务都完成了
reduceDone bool
}
// Map/Reduce任务
type MRTask struct {
Id int
// 任务类型,map/reduce/wait/"",空任务表示作业已经完成,worker可以退出
Type TaskType
// 任务的状态,Waiting/Running/Done
Status TaskStatus
// 任务的启动时间,用于判断是否超时失联
startTime time.Time
// map任务的输入文件
MapFile string
// map任务需要知道有几个reduce任务,从而决定将中间kv数据分区为多少份
NReduce int
// reduce任务的输入文件
ReduceFiles []string
}3.2. Coordinator下发任务
func (c *Coordinator) ApplyTask(args *ApplyTaskArgs, reply *ApplyTaskReply) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if c.mapDone && c.reduceDone {
reply.Task.Type = EmptyType
return nil
}
// 优先下发map任务
if !c.mapDone {
if len(c.mapTasks) == 0 {
// 一个输入文件就对应一个map任务
c.mapTasks = make([]MRTask, len(c.files))
for i, file := range c.files {
c.mapTasks[i] = MRTask{
Id: i,
Type: MapType,
Status: WaitingStatus,
// startTime: time.Now(),
MapFile: file,
NReduce: c.nReduce,
}
}
}
for i, task := range c.mapTasks {
// 从任务列表中选择一个waiting状态的任务下发
// 或者选择一个正在运行但是已经超时的任务重新下发
if task.Status == WaitingStatus ||
(task.Status == RunningStatus && time.Since(task.startTime) > c.timeout) {
c.mapTasks[i].Status = RunningStatus
c.mapTasks[i].startTime = time.Now()
reply.Task = task
return nil
}
}
// 所有map任务都下发了,正在等待map任务完成
// 此时,空闲worker应当暂时等待
reply.Task.Type = WaitType
return nil
}
// map任务都已经执行完了(已写完本地文件)才会下发reduce任务
if len(c.reduceTasks) == 0 {
c.reduceTasks = make([]MRTask, c.nReduce)
for i := 0; i < c.nReduce; i++ {
// 单个reduce worker需要读取来自所有map worker的文件
reduceFiles := make([]string, len(c.mapTasks))
for j := range c.mapTasks {
reduceFiles[j] = fmt.Sprintf("mr-%v-%v", j, i)
}
c.reduceTasks[i] = MRTask{
Id: i,
Type: ReduceType,
Status: WaitingStatus,
ReduceFiles: reduceFiles,
}
}
}
for i, task := range c.reduceTasks {
if task.Status == WaitingStatus ||
(task.Status == RunningStatus && time.Since(task.startTime) > c.timeout) {
// TODO: 如果重新下发任务,不同worker可能会反复写同一份本地文件,这样后续读的时候可能会出现并发读写问题。
// lab中提示了可以用ioutil.TempFile和os.Rename,但貌似即使实现上没有考虑这一点也可以通过测试。
c.reduceTasks[i].Status = RunningStatus
c.reduceTasks[i].startTime = time.Now()
reply.Task = task
return nil
}
}
// 所有reduce任务都下发了,正在等待reduce任务完成
// 此时,空闲worker不能直接关闭,因为某些reduce任务可能会执行失败
reply.Task.Type = WaitType
return nil
}3.3. Worker 申请任务
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
// NOTE: worker类型并非在启动时就固定,而是完全根据coordinator下发的任务类型动态调整
for {
// 1. 向coordinator申请任务
args := ApplyTaskArgs{}
reply := ApplyTaskReply{}
ok := call("Coordinator.ApplyTask", &args, &reply)
if !ok {
fmt.Println("call ApplyTask failed!")
continue
}
// 2. 根据任务类型执行不同的任务
switch reply.Task.Type {
case MapType:
// 2.1 执行map任务
// 2.1.1 读取文件
fileName := reply.Task.MapFile
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("cannot open %v", fileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", fileName)
}
file.Close()
// 2.1.2 执行map函数
intermediate := mapf(fileName, string(content))
// 2.1.3 将map结果写入文件(map worker需要写n个文件)
for i := 0; i < reply.Task.NReduce; i++ {
ofile, _ := os.Create(fmt.Sprintf("mr-%v-%v", reply.Task.Id, i))
for _, kv := range intermediate {
if ihash(kv.Key)%reply.Task.NReduce == i {
fmt.Fprintf(ofile, "%v %v\n", kv.Key, kv.Value)
}
}
ofile.Close()
}
// 2.1.4 通知coordinator任务完成
args2 := TaskDoneArgs{
TaskId: reply.Task.Id,
TaskType: MapType,
}
reply2 := TaskDoneReply{}
ok = call("Coordinator.TaskDone", &args2, &reply2)
if !ok {
fmt.Println("call TaskDone failed!")
continue
}
case ReduceType:
// 2.2 执行reduce任务
// 2.2.1 读取文件
intermediate := []KeyValue{}
for i := 0; i < len(reply.Task.ReduceFiles); i++ {
fileName := reply.Task.ReduceFiles[i]
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("cannot open %v", fileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", fileName)
}
file.Close()
for _, line := range strings.Split(string(content), "\n") {
if line == "" {
continue
}
kv := strings.Split(line, " ")
intermediate = append(intermediate, KeyValue{Key: kv[0], Value: kv[1]})
}
}
// 2.2.2 执行reduce函数
sort.Sort(ByKey(intermediate))
// 2.2.3 将reduce结果写入文件
ofile, _ := os.Create(fmt.Sprintf("mr-out-%v", reply.Task.Id))
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
// 2.2.4 通知coordinator任务完成
args2 := TaskDoneArgs{
TaskId: reply.Task.Id,
TaskType: ReduceType,
}
reply2 := TaskDoneReply{}
ok = call("Coordinator.TaskDone", &args2, &reply2)
if !ok {
fmt.Println("call TaskDone failed!")
continue
}
case WaitType:
// 2.3 等待
time.Sleep(time.Second)
continue
case EmptyType:
// 2.4 退出
return
default:
fmt.Println("unknown task type!")
continue
}
}
}